Research Projects
Our current projects focus on two major thrusts: (1) Security and Privacy of AI and (2) AI for Security (AI-enabled cybersecurity analytics). Our overarching goal is to make cyberspace a safer place. Here we provide a summary of each thrust along with some examples of our work:
Security and Privacy of AI
We are working on (1) making AI models more robust against adversarial attacks with a focus on static malware detectors, (2) making AI model training and LLM fine-tuning robust against data reconstruction attacks using differential privacy.
WARDEN: Information Theoretic Adversarial Training of Large Language Models 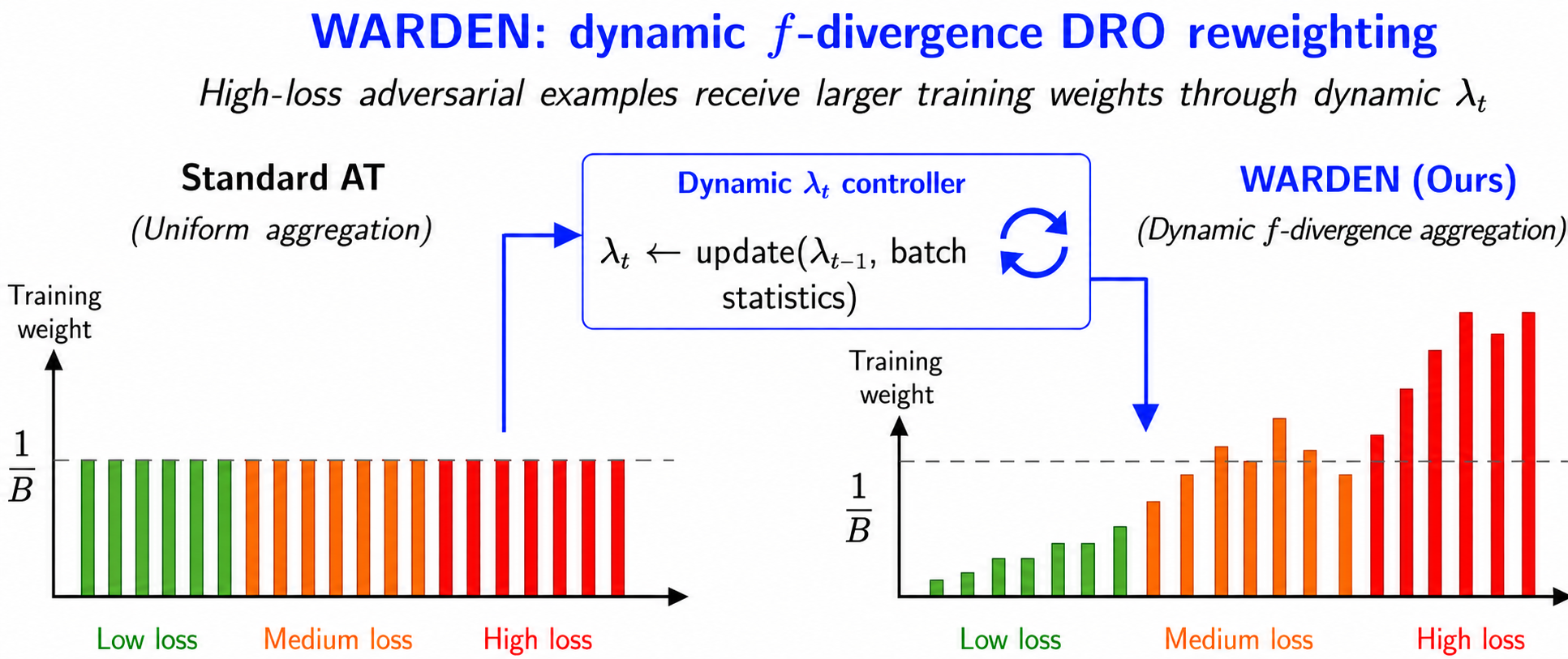
LLMs remain vulnerable to adversarial prompting despite advances in alignment and safety, often exhibiting harmful behaviors under novel attack strategies. While adversarial training improves robustness, existing approaches are computationally expensive and difficult to scale. Recent continuous adversarial training methods, such as Continuous adversarial training (CAT) and Continuous Adversarial Preference Optimization (CAPO), address this challenge by leveraging gradient-based perturbations in the embedding space, enabling more efficient and expressive attacks. Building on this paradigm, we propose WARDEN, a distributionally robust adversarial training framework for LLMs that dynamically reweights adversarial examples through an f-divergence ambiguity set around the empirical training distribution. Our method optimizes the worst-case adversarial loss within a divergence ball around the empirical data distribution, automatically emphasizing harder adversarial examples. Using the convex dual formulation, the objective reduces to a log-sum-exp form under the KL divergence, with a dynamical parameter controlling the strength of reweighting. WARDEN leads to a new class of information-theoretic objectives that significantly reduce attack success rates while maintaining model utility.
You can access the paper here.
RADAR: Adversarially Robust Cyber Defense AI Agents with Deep Reinforcement Learning 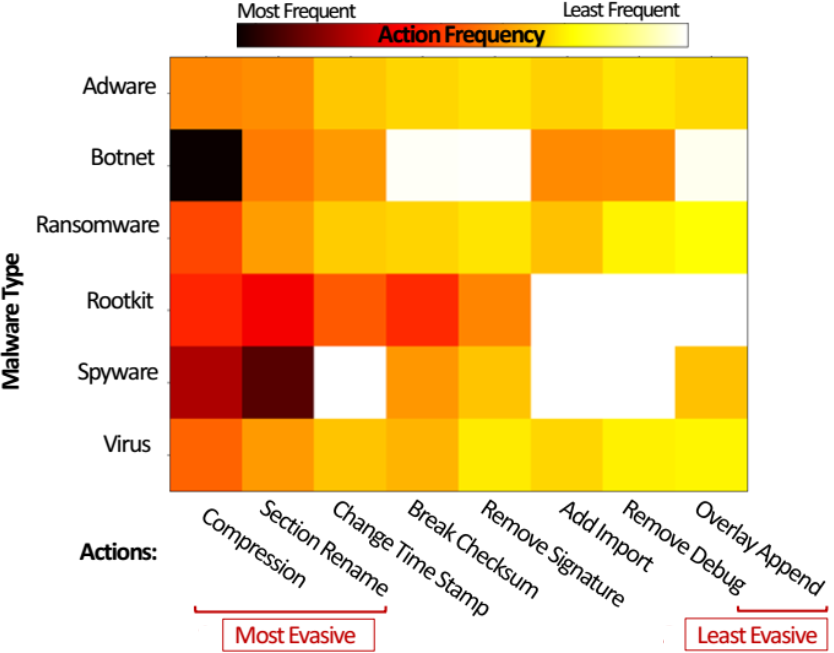
The robustness of cyber defense AI agents has raised deep concerns in modern cyber defense. Drawing on the computational design science paradigm, we couple robust optimization and reinforcement learning theories to develop a novel framework, called Reinforcement Learning-based Adversarial Attack Robustness (RADAR), to increase the robustness of cyber defense AI agents against adversarial attacks. To demonstrate practical utility, we instantiate RADAR for malware attacks – the primary cause of financial loss in cyber attacks. Incorporating RADAR in three renowned malware detectors shows an adversarial robustness increase of up to seven times, on average.
You can access the MISQ paper here.
rsVAC: Risk-Sensitive Variational Actor-Critic 
Risk-sensitive reinforcement learning (RL) with an entropic risk measure typically requires knowledge of the transition kernel or performs unstable updates w.r.t. exponential Bellman equations. As a consequence, algorithms that optimize this objective have been restricted to tabular or low-dimensional continuous environments. In this work we leverage the connection between the entropic risk measure and the RL-as-inference framework to develop a risk-sensitive variational actor-critic algorithm (rsVAC). Our work extends the variational framework to incorporate stochastic rewards and proposes a variational model-based actor-critic approach that modulates policy risk via a risk parameter. We consider, both, the risk-seeking and risk-averse regimes and present rsVAC learning variants for each setting. Our experiments demonstrate that this approach produces risk-sensitive policies and yields improvements in both tabular and risk-aware variants of complex continuous control tasks in MuJoCo.
You can access the ICLR paper here.
AC-CAR: Learning Contextualized Action Representations in Sequential Decision Making for Adversarial Malware Optimization 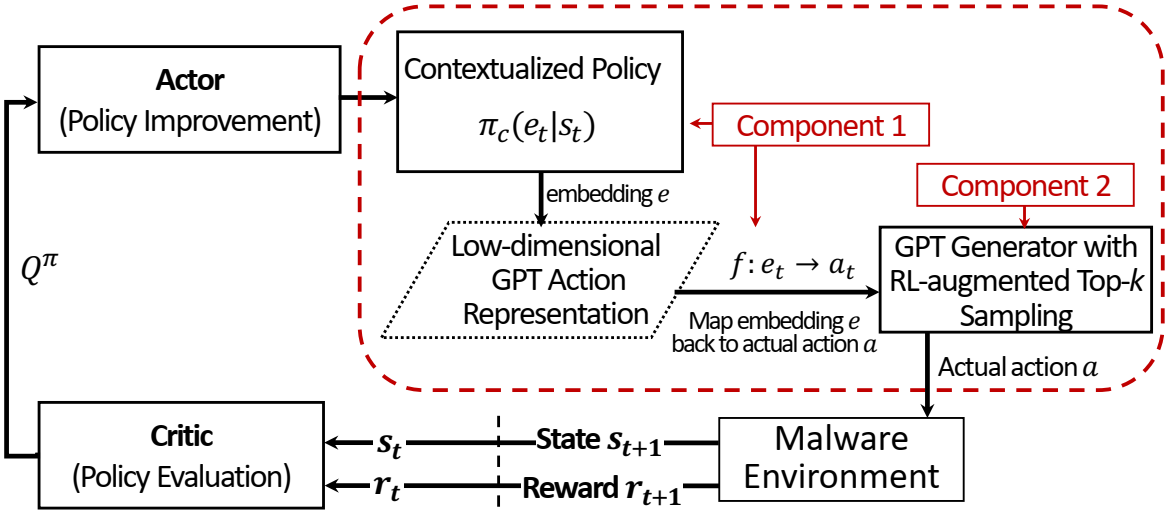
Deep learning (DL)-based malware detectors have been shown to be susceptible to adversarial malware variants generated from meticulously modifying known malware to mislead detectors into recognizing them as benign. Being able to automatically generate optimized functional adversarial malware variants by defenders is crucial to effective cyber defense and staying ahead of the adversary. Current adversarial malware example generation methods often assume threat models with any of the following four restrictions: (1) requiring access to insider knowledge about malware detectors, (2) an unlimited size of adversarial modifications, (3) an unlimited number of queries to malware detector, and (4) relying on dynamic analysis of malware behavior in a sandbox. Drawing on Actor-Critic Reinforcement Learning (RL), we propose a novel black-box binary manipulation method for adversarial malware optimization, named Actor-Critic with Contextualized Action Representations (AC-CAR), to generate malware variants without these restrictions. AC-CAR leverages two novel components, a contextualized policy and a neural language model-based RL-augmented top-k sampling method. Unlike current methods, AC-CAR can utilize tens of thousands of actions to augment malware executables for evading DL-based malware detectors. AC-CAR yields an approximately 2-fold performance increase over the current methods on average, while decreasing the payload size to 20 times smaller than leading methods. We show that using the malware variants generated by AC-CAR in an adversarial re-training procedure improves malware detectors’ robustness against adversarial variants by 29.65% on average.
You can access the TDSC paper here.
ARMOR: Adversarially Robust Learning with Optimal Transport Regularized Divergences 
We introduce the ARMOR methods as novel approaches to enhancing the adversarial robustness of deep learning models. These methods are based on a new class of optimal-transport-regularized divergences, constructed via an infimal convolution between an information divergence and an optimal-transport (OT) cost. We use these as tools to enhance adversarial robustness by maximizing the expected loss over a neighborhood of distributions, a technique known as distributionally robust optimization (DRO). Viewed as a tool for constructing adversarial samples, our method allows samples to be both transported, according to the OT cost, and re-weighted, according to the information divergence; the addition of a principled and dynamical adversarial re-weighting on top of adversarial sample transport is the key innovation of ARMOR. ARMOR can be viewed as a generalization of the best-performing loss functions and OT costs in the adversarial training literature; we demonstrate this flexibility by using ARMOR to augment the UDR, TRADES, and MART methods and obtain improved performance on CIFAR-10 image recognition. On CIFAR-10, ARMOR leads to 1.5\% and 2.1\% increase in adversarial robustness against two strong adversarial attacks, AutoAttack and PGD, respectively. To foster reproducibility, we made the code accessible at https://github.com/star-ailab/ARMOR.
You can see the SIAM paper here. You can also see our ARMOR method at a glance here.
FS-RDP: Differentially Private Stochastic Gradient Descent with Fixed-Size Minibatches 
Differentially private stochastic gradient descent (DP-SGD) has been instrumental in privately training deep learning models by providing a framework to control and track the privacy loss incurred during training. At the core of this computation lies a subsampling method that uses a privacy amplification lemma to enhance the privacy guarantees provided by the additive noise. Fixed size subsampling is appealing for its constant memory usage, unlike the variable sized minibatches in Poisson subsampling. It is also of interest in addressing class imbalance and federated learning. However, the current computable guarantees for fixed-size subsampling are not tight and do not consider both add/remove and replace-one adjacency relationships. We present a new and holistic Rényi differential privacy (RDP) accountant for DP-SGD with fixed-size subsampling without replacement (FSwoR) and with replacement (FSwR). For FSwoR we consider both add/remove and replace-one adjacency. Our FSwoR results improves on the best current computable bound by a factor of 4. We also show for the first time that the widely-used Poisson subsampling and FSwoR with replace-one adjacency have the same privacy to leading order in the sampling probability. Accordingly, our work suggests that FSwoR is often preferable to Poisson subsampling due to constant memory usage. Our FSwR accountant includes explicit non-asymptotic upper and lower bounds and, to the authors’ knowledge, is the first such analysis of fixed-size RDP with replacement for DP-SGD. We analytically and empirically compare fixed size and Poisson subsampling, and show that DP-SGD gradients in a fixed-size subsampling regime exhibit lower variance in practice in addition to memory usage benefits. The implementation of our new privacy accountant is available at https://github.com/star-ailab/FSRDP.
You can see the NeurIPS paper here. You can also see our FSRDP method at a glance here.
Adversarially Robust Malware Detection with Reinforcement Learning 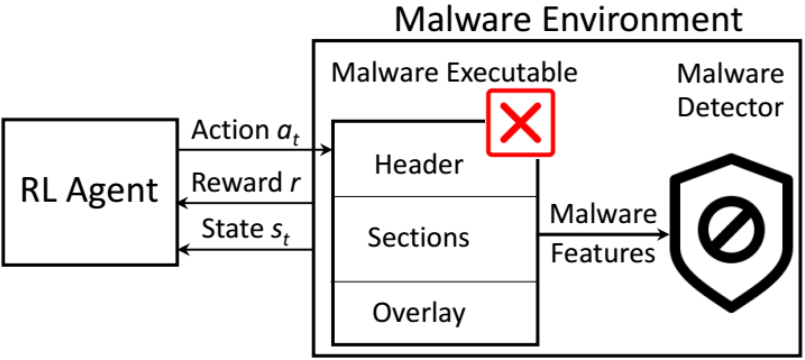
Recent machine learning- and deep learning-based static malware detectors have shown breakthrough performance in identifying unseen malware variants. As a result, they are increasingly being adopted to lower the cost of dynamic malware analysis and manual signature identification. Despite their success, studies have shown that they can be vulnerable to adversarial malware attacks, in which an adversary modifies a known malware executable subtly to fool the malware detector into recognizing it as a benign file. Recent studies have shown that automatically crafting these adversarial malware variants at scale is beneficial to improve the robustness of malware detectors. Most extant methods rely on prior knowledge about the architecture or parameters of the detector, which is not often available in practice. Moreover, the majority of these methods are restricted to additive modifications that append contents to the malware executable without modifying its original content. In this study, we offer a novel Reinforcement Learning (RL) method, which extends Variational Actor-Critic to non-continuous action spaces where modifications are inherently discrete.
e-SeaFL: Privacy-Preserving Federated Machine Learning with Efficient Secure Aggregation 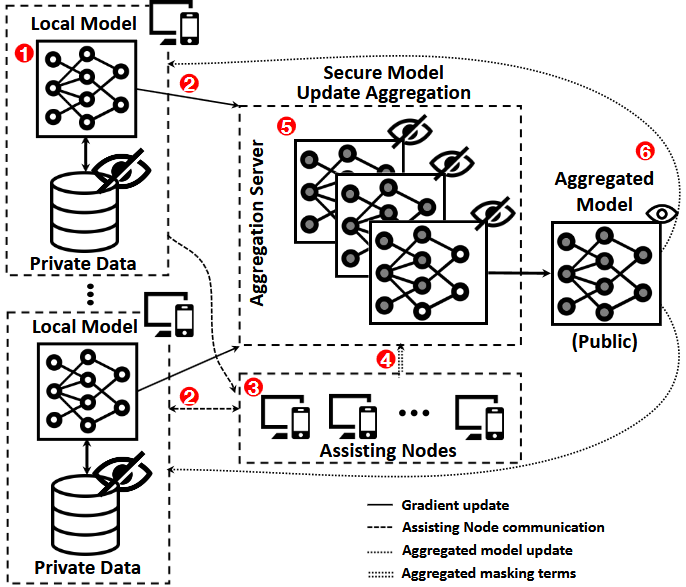
Secure aggregation protocols ensure the privacy of users’ data in federated learning by preventing the disclosure of local gradients. Many existing protocols impose significant communication and computational burdens on participants and may not efficiently handle the large update vectors typical of machine learning models. Correspondingly, we present e-SeaFL, an efficient verifiable secure aggregation protocol taking only one communication round during the aggregation phase. e-SeaFL allows the aggregation server to generate proof of honest aggregation to participants via authenticated homomorphic vector commitments. Our core idea is the use of assisting nodes to help the aggregation server, under similar trust assumptions existing works place upon the participating users. Our experiments show that the user enjoys an order of magnitude efficiency improvement over the state of the art for large gradient vectors with thousands of parameters. Our open-source implementation is available at https://github.com/vt-asaplab/e-SeaFL.
You can see the paper here.
Adversarially Robust Malware Detection with Multivew Representation Learning 
Deep learning-based adversarial malware detectors have yielded promising results in detecting never-before-seen malware executables without relying on expensive dynamic behavior analysis and sandbox. Despite their abilities, these detectors have been shown to be vulnerable to adversarial malware variants - meticulously modified, functionality-preserving versions of original malware executables generated by machine learning. Due to the nature of these adversarial modifications, these adversarial methods often use a single view of malware executables (i.e., the binary/hexadecimal view) to generate adversarial malware variants. This provides an opportunity for the defenders (i.e., malware detectors) to detect the adversarial variants by utilizing more than one view of a malware file (e.g., source code view in addition to the binary view). The rationale behind this idea is that while the adversary focuses on the binary view, certain characteristics of the malware file in the source code view remain untouched which leads to the detection of the adversarial malware variants. To capitalize on this opportunity, we propose Adversarially Robust Multiview Malware Defense (ARMD), a novel multi-view learning framework to improve the robustness of DL-based malware detectors against adversarial variants. Our experiments on three renowned open-source deep learning-based malware detectors across six common malware categories show that ARMD is able to improve the adversarial robustness by up to seven times on these malware detectors.
EW-Tune: Private Fine-Tuninig of Large Language Models 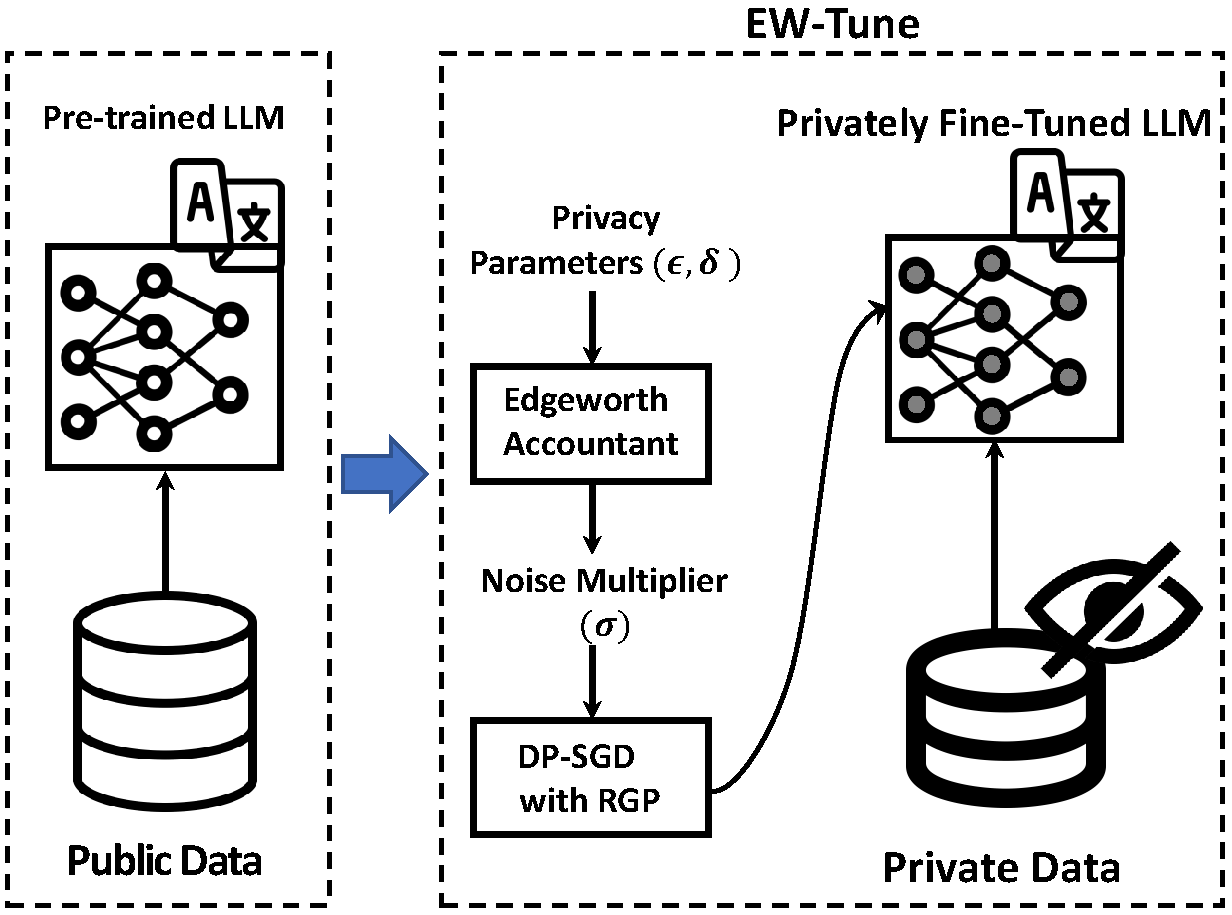
Pre-trained Large Language Models (LLMs) are an integral part of modern AI that have led to breakthrough performances in complex AI tasks. Major AI companies with expensive infrastructures are able to develop and train these large models with billions and millions of parameters from scratch. Third parties, researchers, and practitioners are increasingly adopting these pre-trained models and fine-tuning them on their private data to accomplish their downstream AI tasks. However, it has been shown that an adversary can extract/reconstruct the exact training samples from these LLMs, which can lead to revealing personally identifiable information. The issue has raised deep concerns about the privacy of LLMs. Differential privacy (DP) provides a rigorous framework that allows adding noise in the process of training or fine-tuning LLMs such that extracting the training data becomes infeasible (i.e., with a cryptographically small success probability). While the theoretical privacy guarantees offered in most extant studies assume learning models from scratch through many training iterations in an asymptotic setting, this assumption does not hold in fine-tuning scenarios in which the number of training iterations is significantly smaller. To address the gap, we present EW-Tune, a DP framework for fine-tuning LLMs based on Edgeworth accountant with finite-sample privacy guarantees. Our results across four well-established natural language understanding (NLU) tasks show that while EW-Tune adds privacy guarantees to LLM fine-tuning process, it directly contributes to decreasing the induced noise to up to 5.6% and improves the state-of-the-art LLMs performance by up to 1.1% across all NLU tasks. We have open-sourced our implementations for wide adoption and public testing purposes.
AI-enabled Cybersecurity
ADREL: Multilingual Cyber Threat Detection in the Russian Dark Web with Adversarial Deep Representation Learning 
International dark web platforms operating within multiple geopolitical regions and languages host a myriad of hacker assets such as malware, hacking tools, hacking tutorials, and malicious source code. Cybersecurity analytics organizations employ machine learning models trained on human-labeled data to automatically detect these assets and bolster their situational awareness. However, the lack of human-labeled training data is prohibitive when analyzing foreign-language dark web content. In this work, we develop a novel Cross-Lingual Hacker Asset Detection method that automatically leverages the knowledge learned from English content to detect hacker assets in nonEnglish dark web platforms. Our method encompasses a novel Adversarial Deep Representation Learning (ADREL) method, which generates multilingual text representations using Generative Adversarial Networks (GANs).
HANDA: Multilingual Cyber Threat Detection in Russian and French Darknet Market Places with Adversarial Kernel Matching 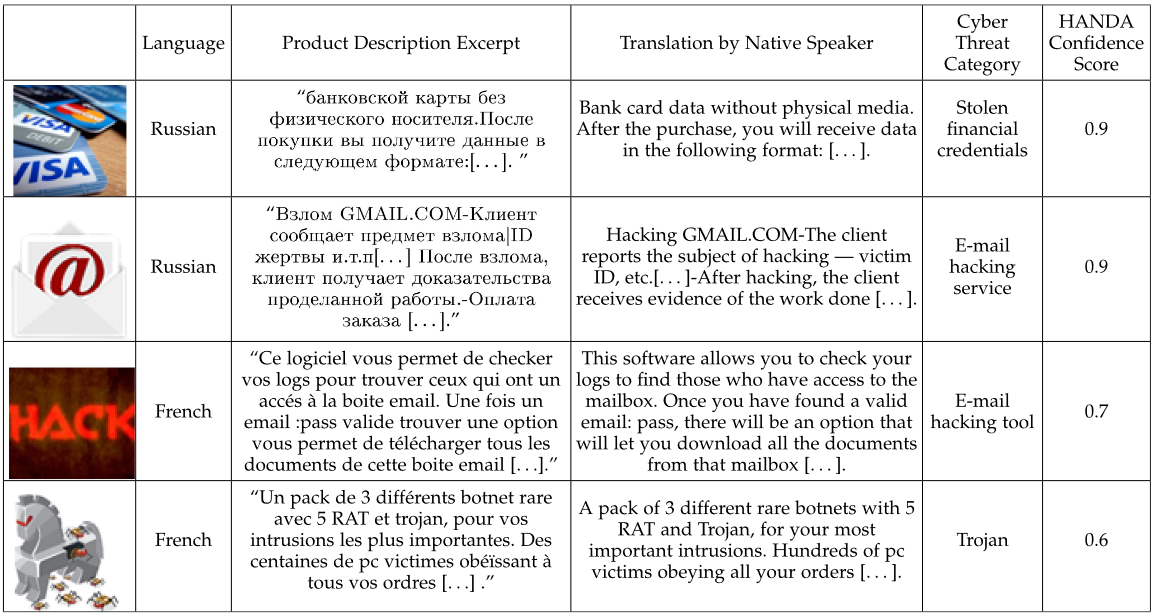
Learning predictive models in new domains with scarce training data is a growing challenge in modern supervised learning scenarios. This incentivizes developing domain adaptation methods that leverage the knowledge in known domains (source) and adapt to new domains (target) with a different probability distribution. This becomes more challenging when the source and target domains are in heterogeneous feature spaces, known as heterogeneous domain adaptation (HDA). While most HDA methods utilize mathematical optimization to map source and target data to a common space, they suffer from low transferability. Neural representations have proven to be more transferable; however, they are mainly designed for homogeneous environments. Drawing on the theory of domain adaptation, we propose a novel framework, Heterogeneous Adversarial Neural Domain Adaptation (HANDA), to effectively maximize the transferability in heterogeneous environments. HANDA conducts feature and distribution alignment in a unified neural network architecture and achieves domain invariance through adversarial kernel learning. Three experiments were conducted to evaluate the performance against the state-of-the-art HDA methods on major image and text e-commerce benchmarks. HANDA shows statistically significant improvement in predictive performance. The practical utility of HANDA was shown in real-world dark web online markets. HANDA is an important step towards successful domain adaptation in e-commerce applications.
